In a recent blog post, we described Cryspen’s new Rust implementation of ML-KEM in Rust, and talked about how our high-assurance development methodology helped us find a new timing bug in various other Kyber implementations.
In this post, we will go into some more detail on how we use the hax verification toolchain to formally prove that our code is panic free and functionally correct.
Background on High-Assurance Cryptography
Cryptographic libraries lie at the heart of the trusted computing base of all networked applications and, consequently, programming bugs in these libraries are always treated as security vulnerabilities, sometimes with high-profile acronyms and news articles. In the past decade, a number of companies and research groups have made a concerted attempt to improve confidence in cryptographic libraries by using techniques from formal verification. This research area, called computer-aided cryptography or high-assurance cryptography, is surveyed in this paper and even has a dedicated workshop.
There are several notable successes from this community effort. Projects like HACL* and Fiat-Crypto generate C code from formally verified implementations written in proof-oriented languages like F* and Coq, and this C code is now widely used in mainstream software including Google Chrome, Mozilla Firefox, Linux Kernel, WireGuard VPN, mbed TLS, Python, ElectionGuard, and Tezos. Other projects like Vale and libjade generate verified assembly code that is as fast or faster than the most optimized implementations in mainstream crypto libraries. Still other projects like CryptoLine seek to verify existing code in important libraries like OpenSSL.
Despite these landmark achievements, many open questions remain. Cryptographic verification tools are largely focused on software written in research languages and it requires Ph.D level skills to verify new cryptographic algorithms. Our verification toolchain hax offers a new way forward targeting implementations written by crypto developers in Rust.
Running the hax toolchain
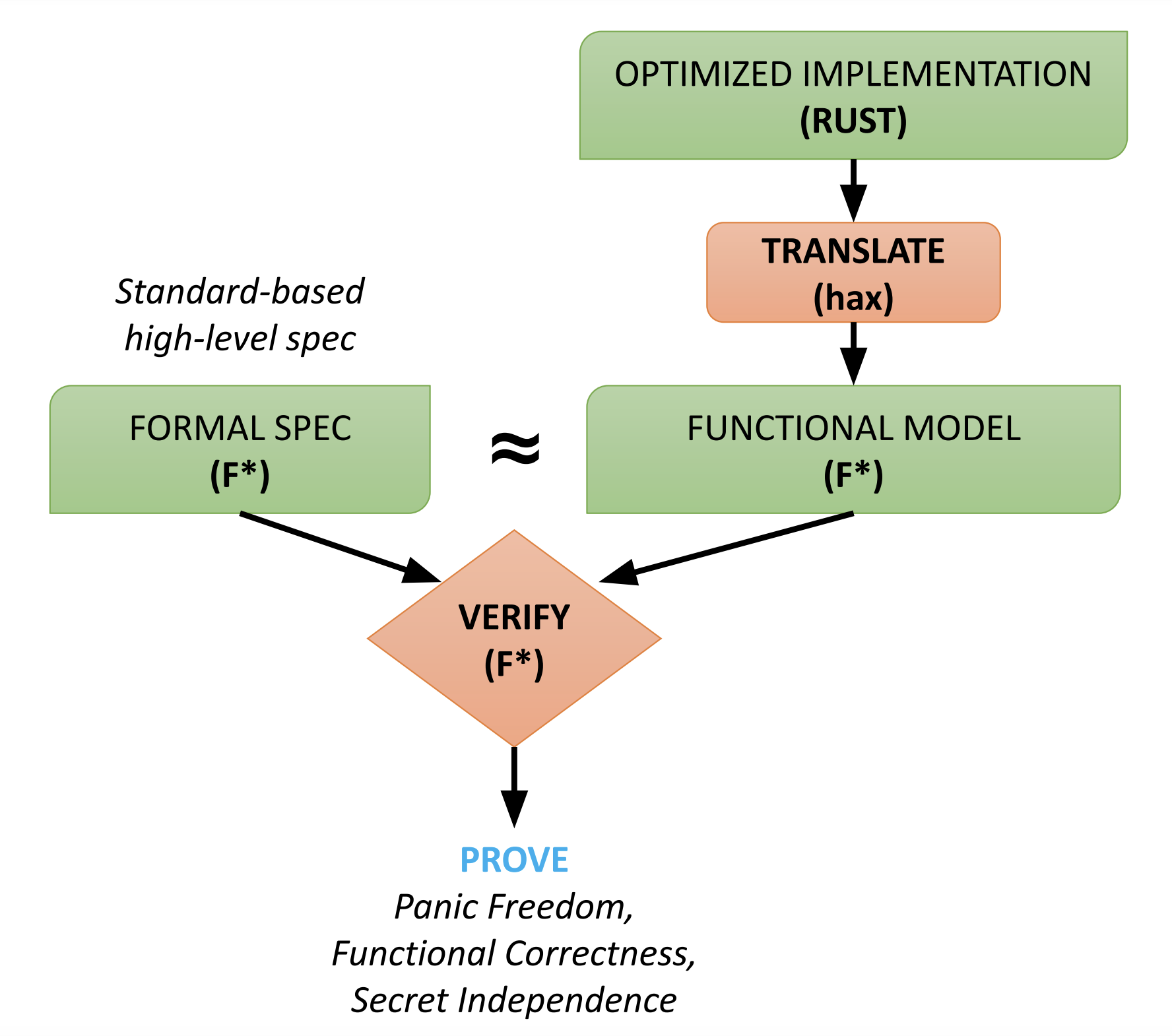
We use the hax toolchain to extract F* code from Rust code. More details on how hax works and its history is in this blog post. The hax toolchain supports multiple backend provers, but for the purposes of this blog post, we focus on the F* backend.
We run hax on the ML-KEM implementation in librux and for each module
M in the implementation, hax produces an F* implementation file
M.fst and a corresponding interface file M.fsti. Each function and
constant in Rust is compiled to an equivalent function and constant in
F*. Each Rust trait turns into an F* typeclass, and each Rust type
is translated to the corresponding type in F*.
Example: Barrett Reduction
As a first example, consider the following function for Barrett reduction,
taken from
the arithmetic.rs file in the libcrux ML-KEM implementation:
pub(crate) fn barrett_reduce(input: i32) -> i32 {
let t = (i64::from(input) * BARRETT_MULTIPLIER) + (BARRETT_R >> 1);
let quotient = (t >> BARRETT_SHIFT) as i32;
let remainder = input - (quotient * FIELD_MODULUS);
remainder
}
This function implements the classic Barrett reduction
algorithm to compute
the modulus of a 32-bit signed integer input with respect to the ML-KEM prime q = 3329.
The algorithm uses the constant BARRETT_R = 2.pow(26) with BARRETT_SHIFT = 26.
In the first line, we multiple the input by a pre-computed constant
20159 (equal to ⌈BARRETT_R/q⌋), and add it to BARRETT_R/2 to
obtatin t. The next line divides t by BARRETT_R to find the
quotient, and the third line computes and returns the remainder.
When we run hax, this function is translated to the
following function in F* (taken from the module Libcux.Kem.Kyber.Arithmetic.fst):
let barrett_reduce (input: i32) =
let t: i64 =
((Core.Convert.f_from input <: i64) *! v_BARRETT_MULTIPLIER <: i64) +!
(v_BARRETT_R >>! 1l <: i64)
in
let quotient: i32 = cast (t >>! v_BARRETT_SHIFT <: i64) <: i32 in
let remainder: i32 =
input -!
(quotient *! Libcrux.Kem.Kyber.Constants.v_FIELD_MODULUS <: i32) in
remainder
As we can see, hax has translated each Rust arithmetic operation (e.g. +) to the corresponding
operation in F* (e.g. +!), and every constant (e.g. 1l), variable (e.g. t) and function (e.g. f_from)
is fully annotated with its complete path and type.
This F* code uses a set of hand-written annotated F* libraries (e.g. Core.Convert) that model
the behavior of the Rust core libraries and operators. These libraries are trusted, but must be carefully
audited to ensure that they correctly reflect the operational semantics of Rust.
Why bother with Barrett Reduction
One may ask why we use a complicated algorithm like Barrett Reduction for a single i32.
Isn’t this algorithm meant only for large integers stored as bignumss?
Why can’t we just calculate the modulus as input % 3329?
The reason we cannot use % is that input is a secret here and division is not a constant-time
operation, as we discussed in our previous blog post.
In F*, we treat i32 as a secret integer type (a public integer must be explicitly labeled as pub_i32), and operations like % are not defined for secret integers. Consequently, the F* typechecker would immediately reject input % 3329 as mal-typed.
We could also use a different modular reduction algorithm, and indeed our code also uses Montgomery reduction, but Barrett Reduction is well-suited for certain computations in Kyber.
Expressiveness and limitations
We note that the F* type system is much more powerful than Rust, allowing the programmer to attach invariants to types (refinement types), pre- and post-conditions to functions (dependent function types) etc., but the hax translation only uses simple F* types by default. As we start doing proofs over this code in F*, we use this expressiveness to extend the generated types with logical annotations.
We also note that although F* has an expressive effect system
to handle stateful code, we only use the purely functional (Tot) effect.
This gives us a significant advantage in being able to prove functional
correctness without worrying about stateful side-effects.
The hax toolchain does not support the full Rust language (at least at present), so for example, if you write a function that relies on delicate pointer manipulation and aliasing in doubly-linked linked lists, it will likely be rejected by hax. However, cryptographic code like ML-KEM primarily performs numeric computations using simple data structures like arrays and structs, with some generalization using generic types, const generics, and traits, and all of these features are supported by hax.
Proving Panic Freedom
Once we have generated F* code from Rust using hax, the verification work begins. Looking again at the Barrett reduction function, we observe that it uses the following arithmetic operations:
- shift right (
>>) - addition (
+) - multiplication (
*) - subtraction (
-)
All of these operations can panic if their arguments are not of the right size.
For example, i32 addition requires that the sum of the two (signed) arguments does not
overflow or underflow the i32 type, otherwise the operation will trigger a panic in
Debug mode and produce a (possibly) unexpected result in Release mode.
In our methodology, we first require that all the code be proved to be panic-free. To do this, we annotate the F* libraries containing these operations with pre-conditions that say that their inputs have to be in the right range. We also provide specifications and lemmas for each operation that models its input-output behavior. For example, right-shift behaves like a division with a power of two, addition maps to arithmetic addition etc.
Then, we run the F* typechecker on the generated code, and it tries to prove these library pre-conditions and if F* fails to prove a pre-condition, it produces a type error, indicating that either the function may panic, or that the prover requires some more annotations or proof hints.
When we run F* on the barrett_reduce function, it uses the library definitions of the operators to prove, in sequence, that:
inputfits in ani64(trivial sinceinput : i32)input * 20159fits in ani64(trivial since both inputs arei32)t = input * 20159 + 2.pow(25)fits in ani64(requires some math reasoning)quotient = t / 2.pow(26)fits in ani32(requires some math reasoning)input - (quotient * 3329)fits in ani32(requires some math reasoning)
Using the annotations and lemmas in our library, F* is able to prove all of the
above automatically using the Z3 SMT solver, and hence it proves
that the barrett_reduce function is panic free.
As we can see, panic-freedom already requires some mathematical and logical reasoning, but it is only the first step towards functional correctness. Often, panic freedom can be proved automatically by F*, but functions with loops, as we see below, require more annotations.
Proving Functional Correctness
To prove that a function like barrett_reduce is correct,
we first need to formally specify its expected input-output behavior.
If the input is a natural number, the Barrett reduction algorithm is
meant to compute input % 3329. However, in our code, input is a
signed integer and may be negative, in which case the remainder is
also a negative value. Furthermore, the way we use this function in
Kyber, we know that the input is always in the range - BARRETT_R <= input <= BARRETT_R.
So, we annotate the type of barrett_reduce (in the interface file Libcux.Kem.Kyber.Arithmetic.fsti) with the types and post-condition shown below:
val barrett_reduce (input: i32_b (v v_BARRETT_R))
: Pure (i32_b 3328)
(requires True)
(ensures fun result ->
v result % v Libcrux.Kem.Kyber.Constants.v_FIELD_MODULUS
= v input % v Libcrux.Kem.Kyber.Constants.v_FIELD_MODULUS)
The refinement type i32_b N is defined as the type of 32-bit
signed integers x:i32 such that -N <= x <= N. So the type
annotation on input is a pre-condition that says that the input
to this function must be in the range -BARRETT_R <= input <= BARRETT_R.
The annotation on the result says that it must be in the range
-3328 <= result <= 3328, and the post-condition in the ensures clause
says that the result is the same as the input modulo the ML-KEM prime (3329).
Proving the functional correctness of barrett_reduce requires more work
from the proof engineer, since we need to use properties of division
and modulus in ways that F* cannot infer automatically. There are many
ways of helping F* complete this proof. One such proof is shown below.
A Proof of Barrett Reduction in F*
The proof is interleaved with the code of the barrett_reduce
function in F*:
let barrett_reduce input =
let t: i64 =
((Core.Convert.f_from input <: i64) *! v_BARRETT_MULTIPLIER <: i64) +!
(v_BARRETT_R >>! 1l <: i64)
in
assert_norm (v v_BARRETT_MULTIPLIER == (pow2 27 + 3329) / (2*3329));
assert (v t = v input * v v_BARRETT_MULTIPLIER + pow2 25);
let quotient: i32 = cast (t >>! v_BARRETT_SHIFT <: i64) <: i32 in
assert (v quotient = v t / pow2 26);
let remainder: i32 =
input
-! (quotient *! Libcrux.Kem.Kyber.Constants.v_FIELD_MODULUS <: i32)
in
calc (==) {
v remainder % 3329;
(==) { }
(v input - (v quotient * 3329)) % 3329;
(==) {Math.Lemmas.lemma_mod_sub_distr (v input) (v quotient * 3329) 3329}
(v input - (v quotient * 3329) % 3329) % 3329;
(==) {Math.Lemmas.cancel_mul_mod (v quotient) 3329}
(v input - 0) % 3329;
(==) {}
(v input) % 3329;
};
remainder
This proof uses assertions (assert) to tell F* to prove some useful logical property,
normalizing assertions (assert_norm) to ask F* to verify a calculation,
and a calculational tactic (calc) to prove the post-condition using lemmas from
the F* math library (Math.Lemmas). This is a fairly simple explicit proof in F*;
it could be further optimized and made more elegant, but it works for the specification we have here and is representative of other proofs we do for our ML-KEM code.
Verifying Properties about Loops
Barrett reduction is a good example of our methodology since it is self-contained and has a clean mathematical specification. However, large parts of the code in ML-KEM (and other cryptographic algorithms) implement algorithms over arrays, vectors, and matrices of values. In these functions, we need to reason about loop invariants to prove that they are panic free and functionally correct.
As an example of this class of code, we consider
another function from arithmetic.rs which adds two ML-KEM
polynomial ring elements:
pub(crate) fn add_to_ring_element(
mut lhs: PolynomialRingElement,
rhs: &PolynomialRingElement,
) -> PolynomialRingElement {
for i in 0..lhs.coefficients.len() {
lhs.coefficients[i] += rhs.coefficients[i];
}
lhs
}
This function takes two polynomial ring elements (arrays of 256 i32 coefficients) called
lhs and rhs and returns the sum of these elements in lhs. For simplicity,
we return lhs here, but of course we could just mutate lhs as well.
To prove that this function is panic free, we require two properties.
First, that the function never accesses lhs or rhs out of bounds.
Since, we only access these arrays at indices i in the right range, F*
can automatically prove these accesses to be safe.
Second, the addition operation + within the loop should never overflow.
F* cannot prove this property, since it indeed does not hold for all inputs.
Consequently, we need to add a pre-condition to the function in F*
that limits the range of inputs it can be called with, and we further need to define
a loop invariant in F* to ensure that this property is preserved as the loop executes.
To specify functional correctness, we add a post-condition to the function that says that the output coefficients are the sum of the input-coefficients. Proving this property also requires us to extend the loop invariant in F*. Details of the proof are below.
Specifying and Verifying add_to_ring_element
The specification for the add_to_ring_element function is:
val add_to_ring_element (#b1: nat) (#b2: nat{b1 + b2 < pow2_31})
(lhs: t_PolynomialRingElement_b b1) (rhs: t_PolynomialRingElement_b b2)
: Pure (t_PolynomialRingElement_b (b1 + b2))
(requires True)
(ensures fun result ->
(forall i. v result.f_coefficients.[i]
== v lhs.f_coefficients.[i] + v rhs.f_coefficients.[i]))
It requires that every coefficient x in the input lhs must be bound by some b1 (-b1 <= x <= b1) and every coefficient y in rhs must be bound by some b2 (-b2 <= y <= b2) such that b1 + b2 < pow2 31.
If this pre-condition holds, then the function produces an output ring element where every coefficient
z is bound by b1+b2 (-(b1+b2) < z < (b1+b2)). Furthermore, the ensures clause states a post-condition that each coefficient in the output is a point-wise sum of the corresponding coefficients in the two inputs.
The F* code and proof of this function is too verbose to include here, but the key element is the loop invariant defined below
let inv = fun (acc: t_PolynomialRingElement_b (b1 + b2)) (i: usize) ->
(forall j. j <. i ==>
acc.f_coefficients.[j]
== lhs.f_coefficients.[j] +! rhs.f_coefficients.[j]) /\
(forall j. j >=. i ==>
acc.f_coefficients.[j]
== orig_lhs.f_coefficients.[j])
It says that after i iterations, the coefficient at every index j < i of the result is the sum of the corresponding values in lhs and rhs, and the coefficient at every index j >= i of the result is the same as the corresponding
coefficient in the original lhs. Once we state this invariant, F* is able to prove the rest of the properties automatically.
Lessons and Benefits of Formal Verification
In this post, we have tried to provide a taste of using hax and F* to verify our ML-KEM Rust implementation. The full implementation is quite large and we are still cleaning up and polishing off the last of our proofs before a final release.
Our experience with ML-KEM shows off several benefits of formal verification:
- Finding bugs and attacks: Our formal analysis resulted in us finding a timing bug in our code, which then pointed the way towards bugs in other implementations of ML-KEM. Although the bug itself does not require deep verification in F*, it does rely on a model of integer arithmetic, and an analysis of how secret information flows through the ML-KEM implementation.
- Code understanding: Our Rust code was comprehensively tested and so we did not expect to find many bugs, but even so, there were several instances where the formal verification found flaws in our assumptions. For example, in some cases, the calculations were much closer to the boundaries of an integer type than we thought.
- Justifying optimizations: Formal verification allowed us to have confidence in the low-level optimizations that we used to speed up our code. For example, in many places in the code, we postpone modular reduction because we can prove that we would not overflow the integer type, and this yields significant performance gains.
In summary, this project shows that formal verification has advantages beyond finding an attack or constructing a proof of a snapshot of the code; it can be used as a constructive part of high-assurance, high-performance cryptographic software development.
To learn more about our methodology, results, or how we can help your project, contact us.
Get in touch