ML-KEM, previously known as Kyber, is the first post-quantum secure key-encapsulation mechanism (KEM) to get standardised by NIST in FIPS 203.
Cryspen has built a new high assurance Rust implementation of ML-KEM, using our verification framework hax and F*. Our implementation is among the fastest portable implementations that we know of (see Performance comparison), and helped uncover a timing bug (also called KyberSlash) in various Kyber implementations that would allow an attacker to recover the private key.
Background on Post Quantum Cryptography
The rise of quantum computing poses a significant threat to current cryptographic systems and protocols. In particular, encrypted network traffic may be subjected to store-now-decrypt-later attacks, where encrypted data is collected by the adversary now so that it can be decrypted later, maybe in several years, when quantum computers become powerful enough to break the public key cryptographic schemes we currently use to establish encryption keys.
To address this challenge, post-quantum cryptography (PQC) has emerged as an essential field aiming to develop cryptographic algorithms that remain secure against both classical and quantum computers. In 2016, NIST initiated a process to solicit, evaluate, and standardise one or more quantum-resistant public-key cryptographic algorithms, and the first draft standards have started to appear. FIPS 203 standardizes a key encapsulation algorithm called ML-KEM (or Kyber), while FIPS 204 (ML-DSA) and FIPS 205 (SLH-DSA) specify digital signature algorithms.
By transitioning to PQC, we can safeguard sensitive information into the quantum era and ensure the continued security of our digital infrastructure. However, because migration of authentication is considered less urgent than key exchange, the community is focused primarily on deploying PQC KEMs right now.
In this blog post, we describe our ML-KEM implementation, tracing the journey from conception to completion, and we detail the timing bug we discovered using our verification framework. Along the way, we discuss the challenges we encountered and briefly outline our verification methodology. A follow-up post will go into the details of the verification.
Implementing Kyber in Rust
We use the terms ML-KEM and Kyber interchangeably in this article, but we implemented the ML-KEM variant that is defined in FIPS 203, not the round 3 submission.
We began this effort in July 2023, before the publication of the NIST draft FIPS 203 that standardizes Kyber into the “Module-Lattice-Based Key-Encapsulation Mechanism Standard” (ML-KEM). We updated both our specification and the optimized implementation to match this draft standard when it was first published, and we continue to track changes to the ML-KEM design.
Kyber specifies 3 parameter sets. To get off the ground, we narrowed our focus to just the 768 parameter set of Kyber (“Kyber768”) and arrived at our first Rust implementation by sticking as closely as we could to the pseudocode in the specification document submitted to round 3 of the NIST post-quantum cryptography standardization effort. This gave us a feel for the algorithm as well as an executable specification that we could use as a reference in our subsequent implementation, debugging and formal verification efforts.
For cryptographic constructions like Kyber, one can write formal specifications at several levels. A high-level mathematical specification may speak about abstract objects like fields, polynomials, vectors, and matrices, without specifying how the arithmetic is implemented over machine integers, or detailing polynomial multiplication algorithms like NTT. NIST specifications like FIPS 203 are tailored towards implementers, and so they do need to provide a certain level of implementation detail in the form of pseudocode, while leaving the choice of hardware platform, or programming language, or data structures to implementers. The goal of the NIST specification is clarity and succinctness, not performance or even security concerns like side-channel resistance.
Our executable specification of Kyber is succinct and testable, but is not suitable for use in a production environment, both for safety and performance reasons.
Towards a fast implementation
In the next step, built a portable implementation of Kyber in Rust, that aims to be at least as fast as the fastest portable implementations currently available.
There is a forbidding set of tips, tricks, and techniques to getting faster Kyber code that are scattered across research papers, doctoral theses, and implementations. With the executable specification as our starting point, we tried to make sense of all these optimizations:
We used cargo flamegraph to identify where our code was spending most of its time, and optimized these areas as much as we could, which largely meant minimizing loop iterations in places like serialization and deserialization and in binomial sampling. This was quite consequential in increasing the performance of our code.
As we started to exhaust the gains from this, we turned our attention to the core operations ubiquitous in the algorithm: the multiplication and modular reduction of field elements. To speed these up, we borrowed a number of techniques from the reference implementation written by the Kyber authors themselves and improved on some of them.
- Using signed instead of unsigned representatives.
Unlike in the PQ-Crystals reference implementation, we store representatives in wider
i32s as opposed toi16s. This allows us to skip more reductions and gave us a net performance gain. - Using signed Barrett and Montgomery reduction.
- Holding off on said reductions for as long as we could (for example, until right before an overflow was about to occur).
- Avoiding conversions from one field-element “domain” to another until we absolutely could not (for example, until right before the result had to be serialized).
- Using signed instead of unsigned representatives.
Unlike in the PQ-Crystals reference implementation, we store representatives in wider
We then used miscellaneous optimizations such as loop unrolling and code-inlining to try and squeeze the last bit of performance out.
Finally, as we began to do formal proofs of the code, we identified new parts of the implementation that could benefit from local optimizations.
Steps 1 and 2 accounted for the majority of our performance gains, followed by the boost we got after step 4.
Implementing the signed modular reduction algorithms and ensuring the correctness of their output bounds presented a significant challenge.
For instance, signed Montgomery reduction involves a seemingly insignificant cast to i16, which carries far-reaching consequences.
If k were instead cast to u16, the bounds of the output would drastically alter.
Furthermore, it proved to be a tedious task to meticulously track the various states and intervals in which field elements could exist throughout the code. For example, are field elements during serialization greater than zero but less than 3329? Are field elements in the inverse in the Montgomery domain?
Despite these challenges, we were emboldened by the knowledge that our code would undergo rigorous scrutiny during our formal verification process. This assurance provided the impetus to push the boundaries in our implementation.
We were also grateful to be able to consult other implementations of Kyber throughout this process, particularly the ones in BoringSSL, CIRCL, as well as the reference implementation by the authors of the algorithm themselves. We were also grateful to the various works that explain some of these implementation techniques.
Adding AVX2 SHA-3
Because SHAKE, the arbitrary length output variant of SHA-3, is a hot path in the Kyber algorithm, we separately implemented a verified 256-bit SIMD variant of SHA-3 in HACL* that allows performing four SHAKE operations at once. This significantly speeds up Kyber on Intel AVX2 platforms. In future, we plan to extend this implementation to with 128-bit SIMD code to support modern ARM CPUs as well.
Interlude: A Plea for Stable Const-Generic Expressions in Rust
Once armed with an optimized implementation of Kyber768, we made it generic over all three parameter sets: this provides additional testing and catches any mistakes arising from “overfitting” our implementation to the 768 parameter set.
The lack of stable const-generic expressions in Rust forced us to precompute most values derivable from the base parameter set and pass them in as generic constants.
Timing Attacks on Kyber (a.k.a. KyberSlash)
A notoriously error-prone aspect of implementing cryptographic algorithms is resistance to timing side-channels. In Kyber, for example, we would like to ensure that an attacker cannot recover secret keys or data by observing the time that it takes for an endpoint to encapsulate or decapsulate a key. While it is quite hard to achieve this goal against a powerful attacker who is able to (say) exploit low-level micro-architectural attacks, it is generally agreed that the minimum necessary mitigation for cryptographic software is secret independence (sometimes called “constant time”). In particular, cryptographic code should never branch on secret conditions or use secret indices to access arrays.
For example, consider the function Compress_d, defined in equation (4.5) of FIPS 203. It maps
an input x to the expression ⌈((2d/q) * x)⌋, where q = 3329 is the Kyber prime.
This function is used in many parts of Kyber, including in the IND-CPA public-key decryption algorithm
to compute the secret message, i.e. the encapsulated key, where x is meant to be secret. However,
a direct implementation of this function would divide a secret value by a constant, which is not guaranteed to
be constant-time on most platforms, and may leak the value of x.
Some compiler and processor combinations may compile this division to a multiplication, but that is not guaranteed.
Indeed, in our own code, we originally implemented this function using a division, but our secret independence analysis (more on that below) flagged it as a potential timing leak. We then surveyed other Kyber implementations and found that even the PQ-Crystals reference implementation of Kyber had this bug, and so did several other implementations in C, Rust, and Go. We informed the Kyber authors, who implemented a fix and we helped propagate this fix to other implementations.
Independently of our work, Dan Bernstein discovered the same bug a few weeks later and has dubbed it KyberSlash. Other exploits and variants of this attack have since been discovered. Dan maintains a list of vulnerable and fixed implementations on the KyberSlash website.
Secret Independence in Specifications
Should secret independence guidelines be explicitly included within standards like FIPS 203? We certainly think so, since otherwise any implementation that directly encodes the pseudocode in the standard is likely to be insecure. Considering the number of Kyber implementations by expert developers that fell into this trap, this is a serious concern.
Division is not the only potential timing concern: If line 9 of Algorithm 17 in FIPS 203 is
implemented as presented, i.e. using an if branch, it could also pose a security issue.
Formally Verifying the ML-KEM Implementation
With the efficient implementation done, we need to verify that it is secret independent, and that our optimizations did not introduce any flaws.

While hax currently only supports a subset of Rust, we did not encounter many of its limitations in our implementation. However, we did observe that certain Rust code patterns resulted in F* code that proved challenging to verify. To effectively use hax, we adapted our Rust code, for example by refactoring functions into smaller units and avoiding the usage of certain traits and iterators. These modifications were primarily to simplify verification, but sometimes they also improved clarity and structure in the source code.
We then proved three kinds of properties for the generated F* code: secret independence, panic freedom, and full functional correctness. We detail the first of these here, leaving the others to a subsequent blog post.
Verifying Secret Independence
We proved that the F* code generated from our Rust implementation was secret independent, using the same type-based technique that is used in HACL*. The formal security guarantees of this technique are detailed in an ICFP 2017 paper: Verified Low-Level Programming Embedded in F*.
This approach requires every input and output to the cryptographic algorithm to be labeled as public or secret.
By default, we consider all values to be secret, including all the integers (i32, u16, etc.) used in the code.
Values that are meant to be public, such as public keys or ciphertexts, must be explicitly labeled as public (pub_i32, pub_u16, etc.),
or they must be declassified from secret to public. Declassifications are security operations
that must be carefully documented and audited.
Once all inputs and outputs are annotated, the type system can propagate these annotations and check that they are respected by the code. In particular, it ensures that the code never performs:
- arithmetic operations with input-dependent timing (e.g. division) over secret integers
- comparison over secret values
- branching over secret values
- array or vector accesses at secret indices
When analysing our Kyber code, we labeled division and modulus as unsafe operations, but note that on certain platforms, even multiplication may have input-dependent timing and would need to be forbidden over secret inputs.
Division in ML-KEM
There are two places in ML-KEM where secret values are used in a division, when compressing messages, and when compressing ciphertexts. One may assume that ciphertexts are public, and this is what we initially did, but as Prasanna Ravi and Matthias Kannwischer pointed out, IND-CPA ciphertexts are not always public in ML-KEM, for example during decapsulation. Consequently, the ciphertext compression code must also be secret independent.
Indeed, when we typecheck the F* code compiled from our non-secret-independent ciphertext compression
function in Rust, typechecking fails because the division operation is not allowed on a
value that is marked as secret (see the squiggly lines on the /! operation).
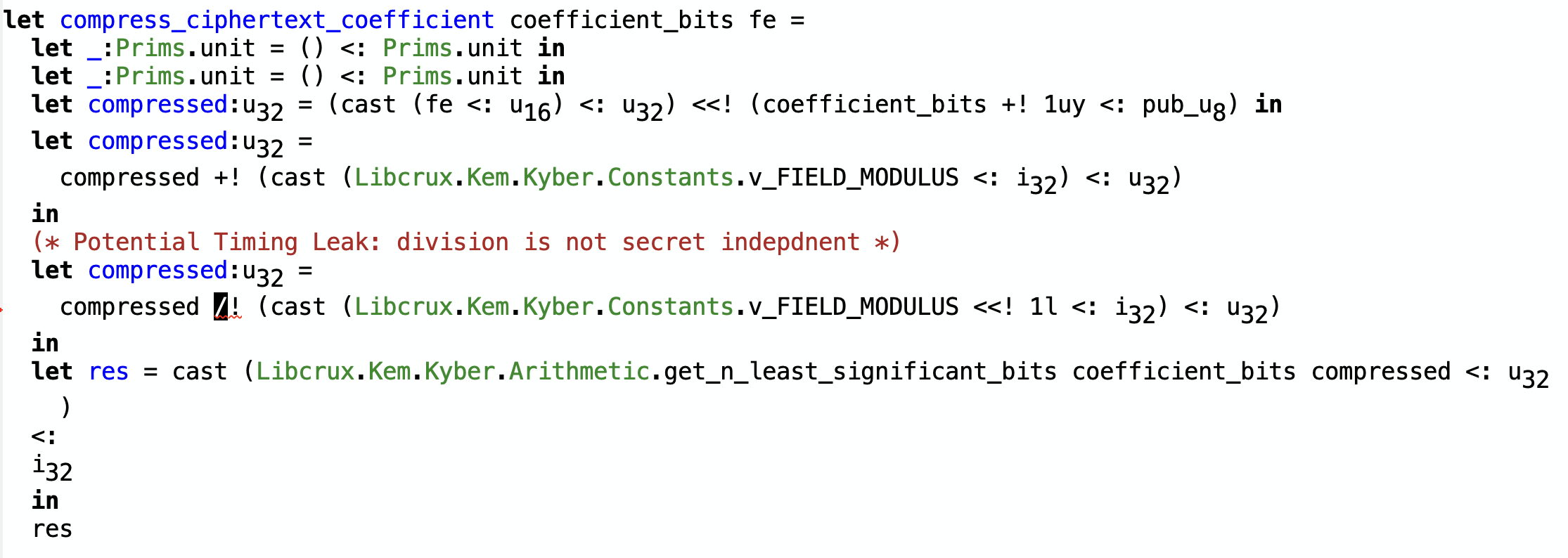
After rewriting all divisions into safe operations, typechecking for this code goes through, which means that there are no divisions or other offending operations over secret values.
However, F* still finds two potential leaks in another function during sampling, where secret random inputs are compared against the field modulus, and values outside the field are discarded. After careful inspection, we decided that these are false positives, in the sense that the discarded values have no further role in the algorithm and hence do not constitute a timing leak. Consequently, we add a declassification to allow this comparison. We note, however, that this kind of declassification is always dangerous and should be carefully reviewed.
Lessons from the Timing Bug
The timing bug we found in Kyber highlights two different issues.
First, it is important to think about secret independent implementations when designing algorithms like Kyber, and when writing specifications like FIPS 203. In this case, no one, from the designers to the specification authors caught the timing bug, and it made its way into multiple implementations, some of which were used in production. Consequently, we advocate that guidelines for secret independence should be included in the standard.
Second, our approach to formal verification helps finding issues like these that are sometimes missed even by designers and security experts. We also note that the verified implementation of Kyber in libjade is also provably secret independent, which speaks for the value of formal analyses.
Benchmarking Performance
Benchmarking our implementation of Kyber768 on a 2021 M1 Pro MacBook yields:
- 28.336 μs for key-generation
- 29.222 μs for encapsulation
- 31.635 μs for decapsulation
The biggest bottleneck in our code is in the rejection sampling that takes place during key-generation and encapsulation: our implementation samples the required blocks of SHAKE (the extendable output function) in one call. This can be seen by looking at the flamegraph for Kyber768 encapsulation.

Most of the time is spent in ind_cpa::encrypt, where 39.67% of the time is spent in Hacl_Hash_SHA3_Keccak and 12.46% of the time is spent in Hacl_Hash_SHA3_state_permute.
We will add a SHAKE API that allows us to obtain output blocks incrementally over multiple calls to the function; this will considerably speed up key-generation and encapsulation, as well as decapsulation since it involves re-encrypting the ciphertext.
Performance comparison
Comparing the performance of our implementation in libcrux with other implementations, we see that our implementation is not only formally verified, but also as efficient as other implementations out there. All benchmarks can be found on Github.
Note that we use a rejection sampling seed size of 168 * 5.
This has a lower error probability than 168 * 4 used in other implementations, respecting the theoretical bounds shown in the Kyber terminates paper.
Lowering our rejection sampling seed size to 168 * 4 makes our implementation even faster.
| MacOS M1 Pro | libcrux | PQClean | BoringSSL | Circl |
|---|---|---|---|---|
| Key generation | 28.336 | 30.387 | 32.051 | 39.783 |
| Encapsulation | 29.222 | 38.688 | 28.131 | 44.874 |
| Decapsulation | 31.635 | 43.072 | 33.777 | 50.025 |
| Linux i5-8350U | libcrux | PQClean | BoringSSL | Circl |
|---|---|---|---|---|
| Key generation | 62.468 | 67.769 | 71.235 | 65.113 |
| Encapsulation | 67.239 | 85.151 | 72.714 | 73.104 |
| Decapsulation | 79.651 | 97.978 | 80.829 | 82.305 |
Extracting C Code
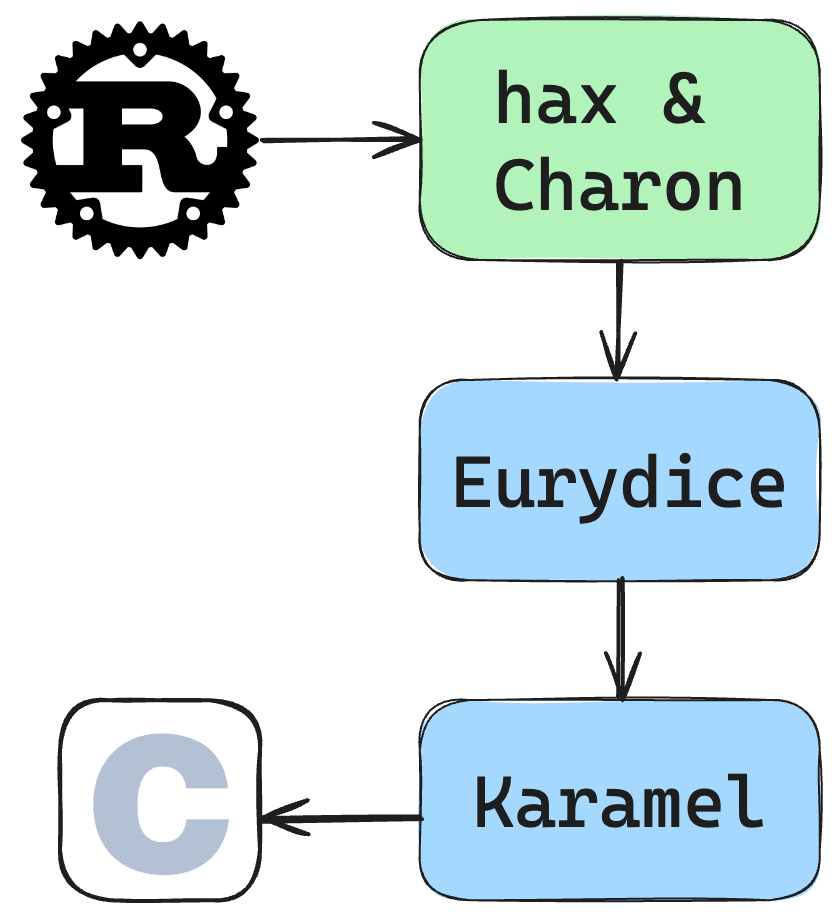
While we wholeheartedly endorse the Rust implementation of ML-KEM in libcrux, the versatility of C necessitates its continued usage in certain scenarios. For instance, we are currently integrating the extracted C code into Mozilla’s NSS library.
To achieve this integration, we leverage the well-established karamel toolchain, which is widely employed for generating C code from HACL*. To enable seamless integration with Rust, we employ a novel tool developed by karamel’s author and Cryspen advisor Jonathan Protzenko. This tool, named Eurydice, translates the extracted Rust AST into a format compatible with karamel, and generates corresponding C code.
We continue to work on improving the readability of the extracted C code and to expand the subset of Rust we can translate, but the performance of the extracted C code remains remarkably comparable to its Rust counterpart.
Embracing High-Assurance PQC
We believe that the adoption of high-assurance PQC implementations is essential for securing our digital infrastructure in the face of the quantum computing threat. We encourage organizations to begin transitioning to PQC solutions as soon as possible and to prioritize high-assurance implementations from the start.
Our team is well-versed in developing and verifying PQC algorithms, and we are eager to assist organizations in their PQC journey. Contact us today to learn more about our services and how we can help you safeguard your sensitive information.
Get in touch