In this blog post we announce an executable specification in the
hacspec specification language for the ScrambleDB pseudonymization
system, developed by Cryspen as part of the BMBF ATLAS project.
Find the specification at our GitHub repository.
First, we will motivate the need for utility-preserving
pseudonymization. Then we will describe how ScrambleDB addresses the
issues found with conventional pseudonymization approaches. We
conclude with a demo of our executable specification that takes you
through a full protocol flow running right here in your browser.
The Need for Utility-Preserving Pseudonymization
In data analysis, pseudonymization of data records is a standard practice to protect the privacy of people whose data is subject to analysis. As a basic precaution against privacy threats, personal identifiers are removed from the data and replaced with non-sensitive pseudonyms.
Areas where pseudonymization of sensitive data is mandated by law in the United States are e.g. in the context of medical data (via HIPAA) or financial transactions (PCI DSS). In Europe, the General Data Protection Regulation (GDPR) recommends pseudonymization as one way to safeguard personal information.
To preserve as much of the utility of the original data, pseudonymization should allow linking data belonging to the same original entity for the purposes of running a specific analysis. The simplest way to achieve this is to pseudonymize sensitive identifiers consistently across all data sets they occur in.
This approach, however, raises several issues:
- A record must be kept of the mapping between sensitive identifiers and their pseudonyms, pseudonymization of new data must be performed consistently in order preserve data utility. If this record is misappropriated or leaked during a data breach all pseudonymization can be fully undone with potentially huge harms to privacy.
- While subsets of the pseudonymized data can be given out selectively for different analysis, this incurrs a piece-meal privacy degradation with every analysis performed, since consistent pseudonymization allows linking the data between different analysis, potentially revealing more information about the subjects than the data for any single analysis.
Cryptography to the Rescue: ScrambleDB
ScrambleDB is a cryptographic solution for consistent and utility-preserving pseudonymization of sensitive information which was introduced by Anja Lehmann in her paper ScrambleDB: Oblivious (Chameleon) Pseudonymization-as-a-Service published in Proceedings of Privacy Enhancing Technologies 2019.
ScrambleDB operates on tables of data provided, stored and/or
requested by different protocol parties. A table is a collection of
attribute entries for entities identified by unique keys. The original,
unpseudonymized data is provided by Data Sources to a Data Lake where
they should be stored in pseudonymized form. Data Processors can make
requests to the Data Lake to receive a subset of the pseudonymized
data for analysis.
To realize this, there are sub-protocols for converting between different table types:
Conversion from original tables to pseudonymized columns
An original unpseudonymized table contains attribute data addressed by
(possibly sensitive) entity identifiers, e.g. a table might store
attribute data for attributes Address and Date of Birth (DoB)
under the entity identifier Full Name.
ScrambleDB pseudonymization of such a table can be thought of as
computed in two steps:
Splitting the original table by attributes, resulting in single-column tables, one per attribute, indexed by the original identifier.
Pseudonymization and shuffling of split columns, such that the original identifiers are replaced by pseudonyms which are different and thus unlinkable between different columns.
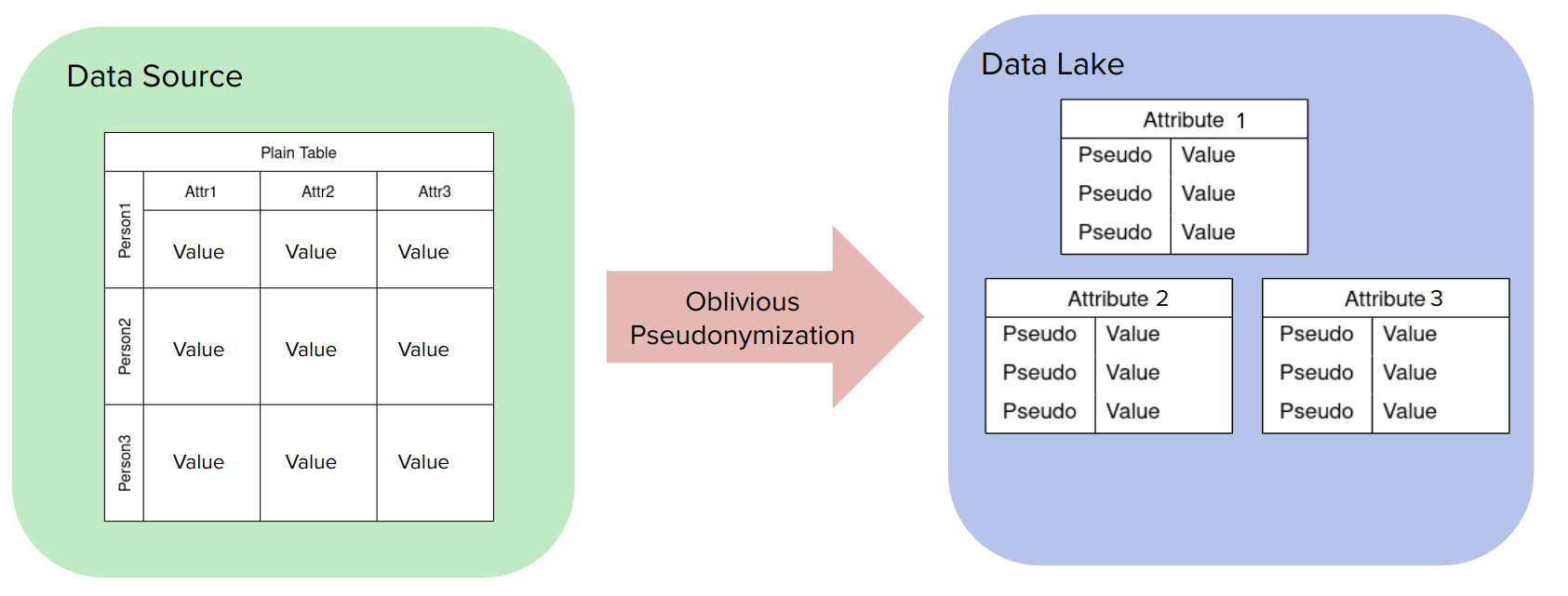
Since the result of pseudonymizing a plain text table is a set of pseudonymized single-column tables we refer to this operation as a split conversion.
Conversion from pseudonymized columns to non-transitively joined tables
Pseudonymized columns may be selectively re-joined such that the original link between data is restored, but under a fresh pseudonymous identifier instead of the original (sensitive) identifier.
Join-pseudonyms are fresh for each join and are thus non-transitive, i.e. it is not possible to further join two join-results based on the join pseudonym.
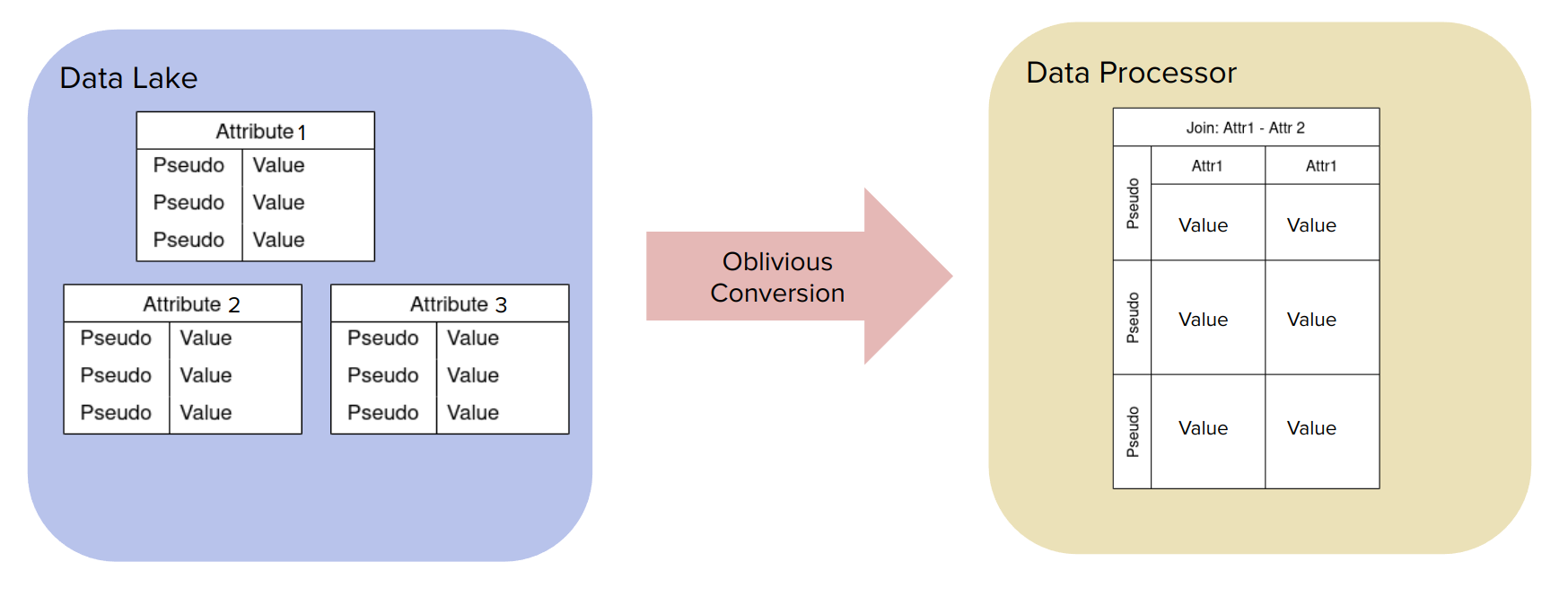
Since the result of this conversion is a joined table, we refer to the operation as a join conversion.
Performing ScrambleDB Pseudonymization Obliviously
The above approach to pseudonymization addresses the problem of oversharing data during analysis by only re-linking pseudonyms for the actual data the is necessary to serve a join-request. Further, the data stored in unlinkable pseudonymized tables minimizes the risk of data breaches leading to the dissemination of linkable (if pseudonymized) data present with the naive approach.
To implement the pseudonymization regime, however, the question arises
how to generate unlinkable pseudonyms which can still be selectively
re-linked without re-introducing the problem of the Data Lake having
to keep a record of the links between different pseudonyms. For this
reason, ScrambleDB introduces a fourth participant in the
pseudonymization process, which converts original identifiers to
unlinkable pseudonyms and unlinkable pseudonyms to non-transitively
linkable join-pseudonyms. This entity is thus aptly named the
Converter and performs its conversion operations fully oblivious to
both the pseudonyms and the data that pass through it.
The clever piece of cryptography which allows the Converter to work fully obliviously is called Convertible Pseudorandom Function (CoPRF). Like a regular oblivious pseudorandom function (OPRF), it allows the oblivious evaluation of a pseudorandom function such that the evaluator learns neither the input nor the output that he obliviously computed. Unlike a regular OPRF, where the input is provided by a requester and that same requester wants to learn the output, in a CoPRF, the requester asks for the PRF to be obliviously evaluated towards a third party, the receiver of the PRF output, who in turn will not learn of the original input.
In ScrambleDB, this means a Data Source can ask for the oblivious generation of pseudonyms, i.e. PRF outputs, towards the Data Lake. Because of the security properties of the CoPRF, the Data Source will not learn the generated pseudonym, the Data Lake will not learn what the original identifier was and the Converter will learn nothing at all.
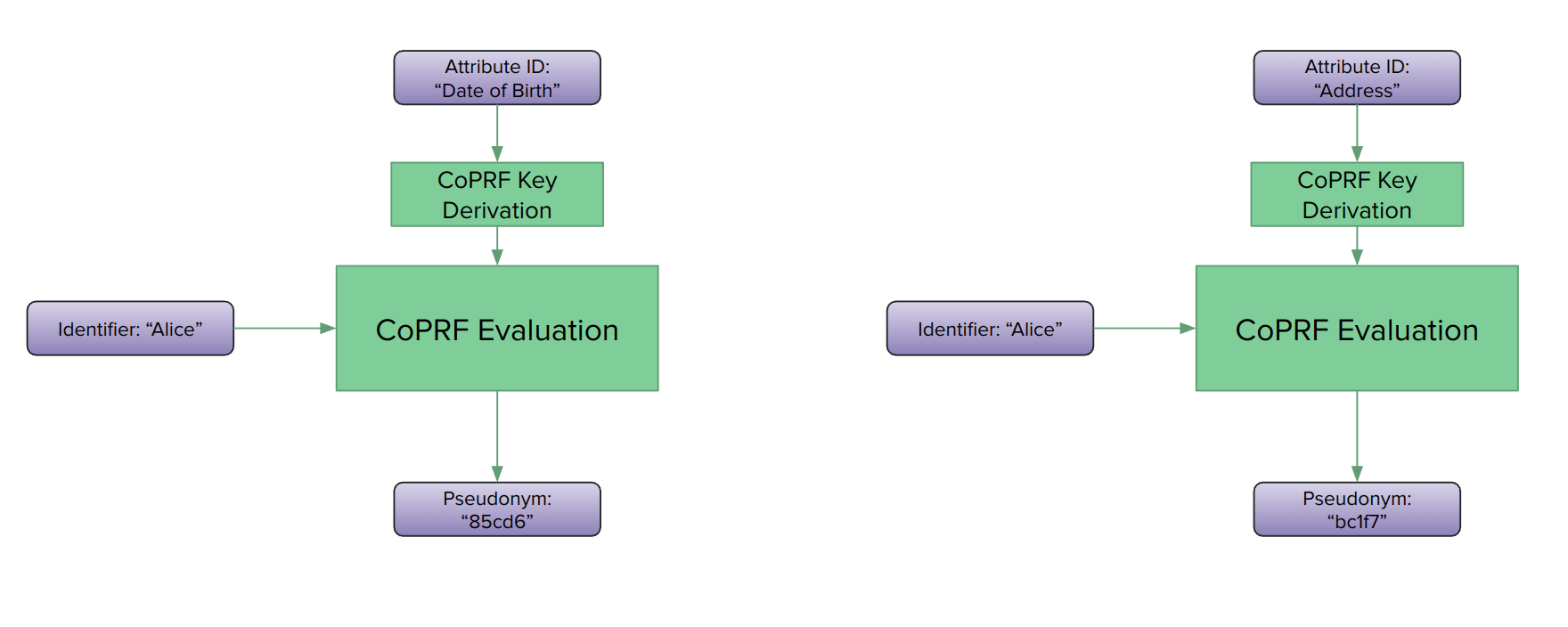
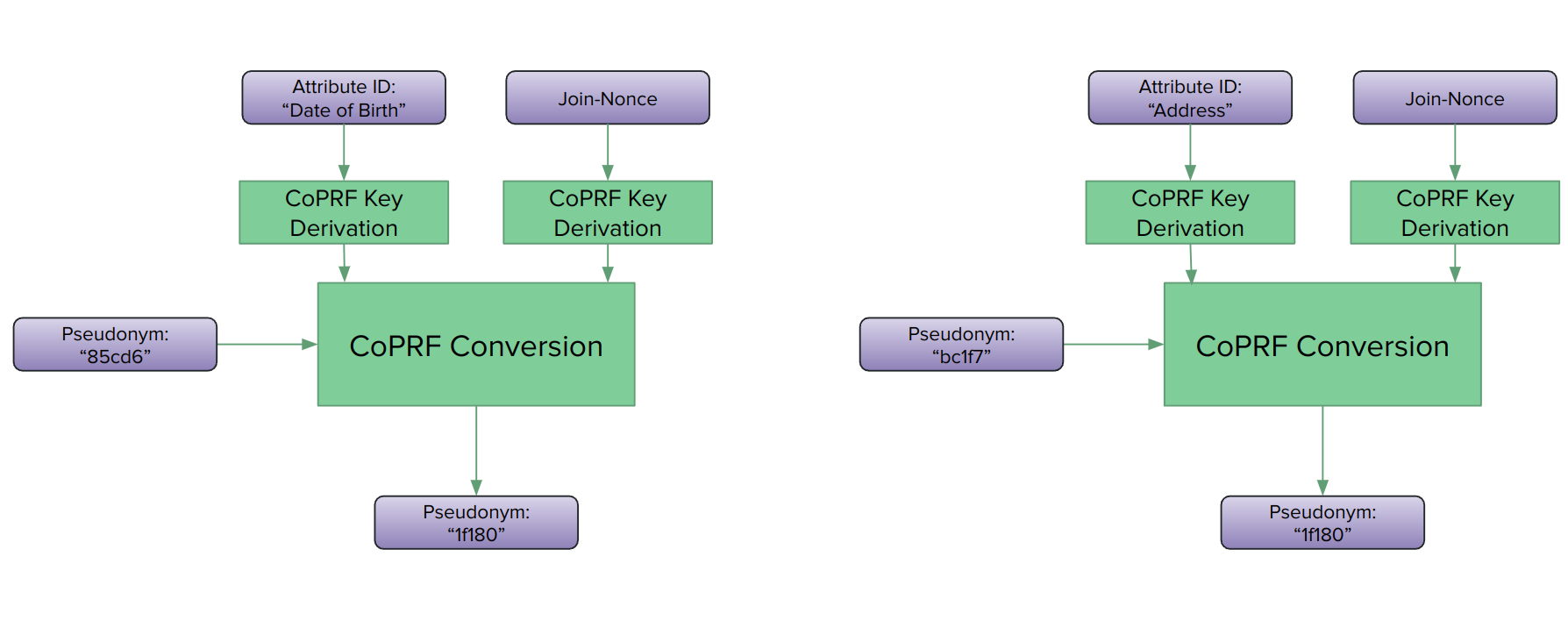
The second handy property of CoPRFs is the convertibility property hinted at by the name of the technique. Intuitively it means that PRF outputs generated under a given evaluation key can be obliviously converted from that original key to a different key (as long as you know both keys.) For the initial pseudonymization we have different evaluation keys for different identifier-attribute pairs, hence different, unlinkable pseudonyms. In the join subprotocol, these different pseudonyms are converted to a common, ephemeral evaluation key that is unique to the given join request. Again, because of the security properties of the CoPRF, the Data Lake will not learn the resulting join-pseudonyms, the Data Processor will not learn the pseudonyms as they are stored at the Data Lake and the Converter will be fully oblivious during the conversion.
Demo
The demo below runs the executable specification right here in your browser.
You can edit the values in the table below and follow them through the
protocol stages once you push the Read Table button.
At each stage we include a small snippet of code that illustrates roughly how the data transformation is modelled in our specification API. Note that it may take a few seconds to compute everything after clicking the “Read Table” button.