Cryspen builds high assurance cryptography. But what does this actually mean?
Before focusing on cryptography it is interesting to look at high assurance software in general. How is high assurance software different from other software?
High assurance software is usually seen as being more trustworthy than other software. This is especially interesting in high-risk/high-stakes environments such as financial institutions or governments. There are different ways to achieve better guarantees for software. Today the most commonly used technique to increase trust into software is using certifications like common criteria or FIPS. While these certifications offer a certain level of additional guarantees, only the highest levels require some form of formal verification of the production source code. As such certification usually reaches only up to a certain level of high assurance.
Instead, using formal methods to increase trust in software offers real tangible guarantees on a software artifact. But in order to get actual guarantees we have to define the properties that are guaranteed and put it into perspective by defining different assurance levels. Before doing this we look at the different techniques used in high assurance software engineering.
Techniques
There are a number of different techniques used in (high assurance) software engineering. Some are simply good engineering practice while others go beyond what is done for most software. The following picture gives a high-level overview of the different techniques. (The list is of course not exhaustive and some grouping might be arbitrary.)
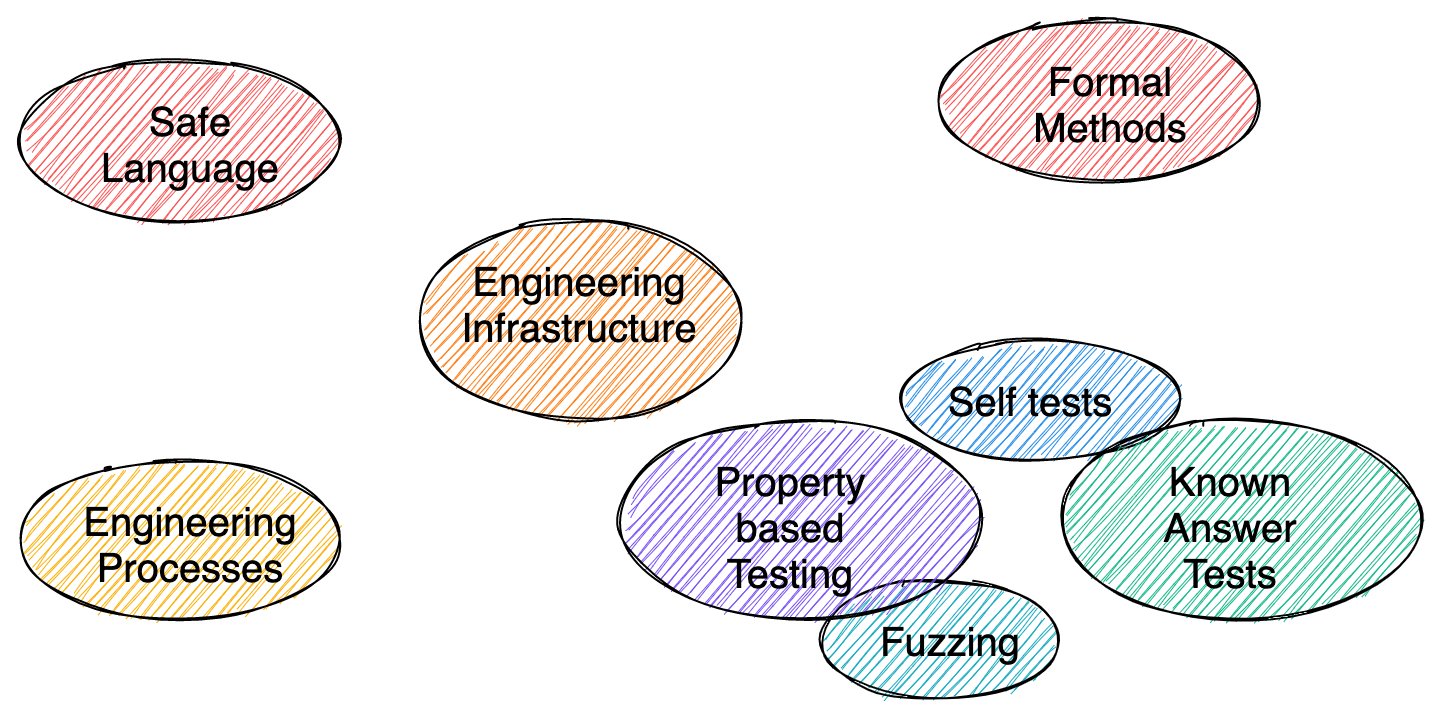
On the left side we have safe programming languages and engineering processes that are the bedrock of high assurance software engineering. Processes ensure that the development and maintenance process is safe while using a safe programming language such as Rust that gives memory safety guarantees provides a safety baseline for the software.
The engineering infrastructure in the center is used to enforce policies and link everything together. It is the glue that implements engineering processes and ensures safe operations of the code at all times. On the right hand side we have engineering practices divided into dynamic and static tools, or testing and formal methods. There are a lot of different testing techniques from fuzzing to known answer tests that ensure that the code is operating correctly and safely for a certain set of inputs. With static analysis and formal methods we can go a step further and ensure that the code is correct and safe for all inputs.
Assurance Levels
Speaking about “high assurance” is so vague that it can be considered meaningless. When speaking about high assurance software it is paramount to define a set of properties the software guarantees. To this end we define a set of assurance levels a software artifact can achieve and a set of techniques used to get there. The following picture sorts the previously defined techniques according to the level of assurance they provide and the complexity required to use them.
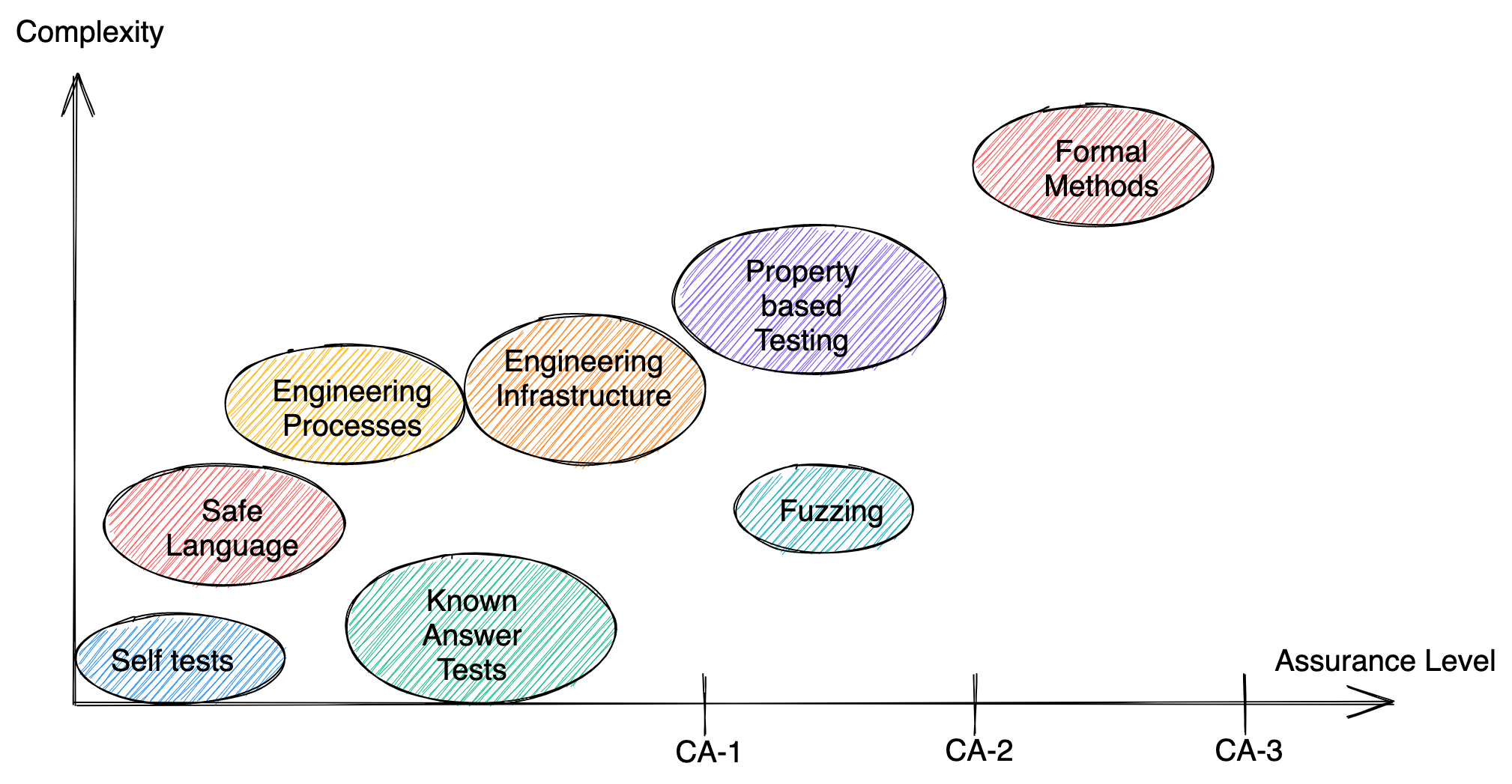
CA-1
The first level of high assurance software is what I’d flippantly call “well written software”. At this level no complex tools are required. Instead good engineering principles are applied.
Note that this level must not be used for cryptographic software. Cryptography requires at least CA-2.
The programming language and how it is used is the first important point. A programming language like Rust that is memory safe and has a lot of additional features that allow to ensure that the code is “safe” is paramount. It is well known that memory safety is the root cause for most security issues with about 70% (see what Google, Microsoft, or the ISRG say about this). They are only possible because languages like C and C++ are not memory safe.
The code requires a sufficient amount of tests. It is difficult and arbitrary to define an exact number for test coverage. But I think it is safe to say that a test coverage of less than 70% is not acceptable. Defining test coverage, quantitatively and qualitatively, is part of the engineering process.
Because testing against itself is not sufficient, test vectors with known answer tests must be used. If the implementation does not have a generally accepted specification or (de-facto) reference implementation that can be used to get test vectors, a reference implementation (specification) must be written to produce test vectors.
Engineering processes must be implemented that ensure that the code can be safely maintained in the long-run. An engineering infrastructure must be in place to enforce processes and help the engineering process.
Properties:
- Memory safety
- Adequate test coverage
- Known answer tests
- Engineering best practices
- Review guidelines
- Continuous integration
- Documentation
- (Security) bug reporting
- Release management
CA-2
The second level includes everything from the first level but adds properties specific to cryptographic code and more advanced testing methods.
In cryptographic code it is important that no decisions are made based on secret information. It is therefore necessary to avoid any branching on secret data or memory access based on secret data. There is research tooling out there that tries to ensure this and a lot of good practices to avoid it. But there’s no comprehensive way of doing this right now. With Cryspen we develop a set of tools to ensure secret independent computation that we use and maintain.
On this level more advanced testing such as fuzzing and property based testing is required as well to make sure that the code is not only safe in well defined states but can handle any input.
Properties:
- Secret independent computation
- No secret-dependent branching
- No secret-dependent memory access
- Advanced testing
- Fuzzing
- Sanitizer builds
- Property based testing
CA-2+
The secret independent computation properties in CA-2 can be shown on different levels. Often this is done only on the programming language level rather than the machine code. If the secret independent computation is ensured on the machine code level, we call this CA-2+. Higher levels are augmented with the + in the same way if the secret independence is given after compilation.
Properties:
- Secret independent computation ensured on the machine code level
CA-3a
The third assurance level includes the first two but requires formal methods. This is what we will always aim for. But because of the complexity and real world constraints it is not always feasible to achieve this level for all code.
Cryptographic primitives are one building block used to build cryptographic protocols. Because they require highly efficient implementations but usually have a rather succinct mathematical definition, functional and semantic correctness are the properties we are interested in. In particular, the efficient implementation of a cryptographic primitive must be shown equivalent to a self-evidently correct specification. Additionally semantic properties such as “decryption is the inverse of encryption” can be shown. The exact properties proven must be clearly stated for every artifact.
Data structures and other building blocks are needed to build cryptographic protocols in addition to the primitives. They must be similarly shown to be correct and safe to use by using functional and semantic correctness proofs.
On this level the cryptographic protocols themselves are written in a succinct way such that they can be inspected by hand and compared to a general specification if available.
Properties:
- Functional and semantic security proofs
CA-3b
The third level can be extended to require formal proofs on the protocol layer. While cryptographic protocols can often be written in a way that they are self-evidently correct and efficient, this is not enough if the protocol is not standardized or is too complex to inspect manually.
Security models and properties are defined for a protocol and they are proven on the implementation of the cryptographic protocols using formal methods. These properties are very specific to each protocol and can range from the correctness of a state machine to the security against a certain type of attacker.
Properties:
- Security proofs
High-Assurance?
https://highassurance.rs has some great documentation on writing good Rust code. However, it also has a good example of what I don’t consider high assurance software and exemplifies why it is so important to specify all claims precisely instead of simply claiming high assurance. (Note that this is just an example to show why it is so important to exactly specify what assurances are given. This is not supposed to bash the https://highassurance.rs folks. I think it’s a great effort.)
Let’s take a look at chapters 2.4-2.6 that describe a high assurance implementation of the RC4 stream cipher. At the end of the section the authors state the following:
You’ve now built your first piece of high assurance software (sans the RC4 algorithm itself). Your RC4 library is:
- Fully memory-safe, hence
#![forbid(unsafe_code)]- Stand-alone and capable for running almost anywhere, hence
#![no_std]- Functionally validated, using official IETF test vectors
While these points are all on the list above they are what I would consider good engineering principles (known answer tests with test vectors, and memory safety). In particular, they lay the foundation for high assurance software but don’t constitute high assurance in itself. As is, the code itself would be CA-1 but additional mechanisms in the form of engineering processes and infrastructure are needed for full CA-1 compliance. (Similar additional mechanisms are mentioned in Chapter 2.)
However, CA-1 is not sufficient for cryptographic primitives as stated above. To reach CA-2 the code needs to be rewritten though because it has secret dependent memory access. After doing this property based testing, fuzzing, and techniques ensuring secret independent computation have to be added.
Because the code can be seen as a spec one can argue that it reaches CA-3a now as well. CA-3b is not applicable. However it is not very efficient but rather a specification. In order to use the algorithm in a real application one might want to implement an efficient version that would then require an equivalence proof with the specification.
RC4 itself is of course not secure and must not be used! This is just taking the example from https://highassurance.rs.
Cryspen High Assurance Cryptography
At Cryspen we consider CA-1 regular software. Cryptographic code at Cryspen must always be CA-2 or higher.
We are working on different high assurance cryptographic primitives and protocols right now.
HACL
The HACL packages wrap the HACL* research artifacts and constitute a high assurance cryptographic library. The library is CA-3a because it is proven to be memory safe, has correctness proofs with respect to a specification and ensures secret independent computation on a programming language level.
HPKE
The HPKE implementation is a specification of the HPKE RFC and as such is CA-3a because it is self-evidently correct as a specification and uses formally verified cryptography with CA-3a. In a next step the HPKE implementation will be connected to the Cryptoverif models to prove security properties and thus reach the highest assurance level CA-3b.
TLS 1.3
In an NGI Assure project we develop the first formally verified, production ready TLS 1.3 implementation.
Cryspen offers high assurance cryptographic implementations. Get in touch for more information.